Replicating Propubliuca’s COMPAS Audit#
import numpy as np
import pandas as pd
import scipy
import matplotlib.pyplot as plt
import seaborn as sns
import itertools
from sklearn.metrics import roc_curve
import warnings
warnings.filterwarnings('ignore')
clean_data_url = 'https://raw.githubusercontent.com/ml4sts/outreach-compas/main/data/compas_c.csv'
df= pd.read_csv(clean_data_url).set_index('id')
df.head()
| age | c_charge_degree | race | age_cat | score_text | sex | priors_count | days_b_screening_arrest | decile_score | is_recid | two_year_recid | c_jail_in | c_jail_out | length_of_stay | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||
| 3 | 34 | F | African-American | 25 - 45 | Low | Male | 0 | -1.0 | 3 | 1 | 1 | 2013-01-26 03:45:27 | 2013-02-05 05:36:53 | 10 |
| 4 | 24 | F | African-American | Less than 25 | Low | Male | 4 | -1.0 | 4 | 1 | 1 | 2013-04-13 04:58:34 | 2013-04-14 07:02:04 | 1 |
| 8 | 41 | F | Caucasian | 25 - 45 | Medium | Male | 14 | -1.0 | 6 | 1 | 1 | 2014-02-18 05:08:24 | 2014-02-24 12:18:30 | 6 |
| 10 | 39 | M | Caucasian | 25 - 45 | Low | Female | 0 | -1.0 | 1 | 0 | 0 | 2014-03-15 05:35:34 | 2014-03-18 04:28:46 | 2 |
| 14 | 27 | F | Caucasian | 25 - 45 | Low | Male | 0 | -1.0 | 4 | 0 | 0 | 2013-11-25 06:31:06 | 2013-11-26 08:26:57 | 1 |
pd.read_csv(clean_data_url).head()
| id | age | c_charge_degree | race | age_cat | score_text | sex | priors_count | days_b_screening_arrest | decile_score | is_recid | two_year_recid | c_jail_in | c_jail_out | length_of_stay | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 34 | F | African-American | 25 - 45 | Low | Male | 0 | -1.0 | 3 | 1 | 1 | 2013-01-26 03:45:27 | 2013-02-05 05:36:53 | 10 |
| 1 | 4 | 24 | F | African-American | Less than 25 | Low | Male | 4 | -1.0 | 4 | 1 | 1 | 2013-04-13 04:58:34 | 2013-04-14 07:02:04 | 1 |
| 2 | 8 | 41 | F | Caucasian | 25 - 45 | Medium | Male | 14 | -1.0 | 6 | 1 | 1 | 2014-02-18 05:08:24 | 2014-02-24 12:18:30 | 6 |
| 3 | 10 | 39 | M | Caucasian | 25 - 45 | Low | Female | 0 | -1.0 | 1 | 0 | 0 | 2014-03-15 05:35:34 | 2014-03-18 04:28:46 | 2 |
| 4 | 14 | 27 | F | Caucasian | 25 - 45 | Low | Male | 0 | -1.0 | 4 | 0 | 0 | 2013-11-25 06:31:06 | 2013-11-26 08:26:57 | 1 |
df['decile_score'].mean()
4.6227737779461915
df.groupby('race')['decile_score'].mean()
race
African-American 5.276850
Caucasian 3.635283
Name: decile_score, dtype: float64
race_score_counts= df.groupby('race')['decile_score'].value_counts().unstack()
race_score_counts.T.plot(kind= 'bar',figsize= (12,7))
<Axes: xlabel='decile_score'>
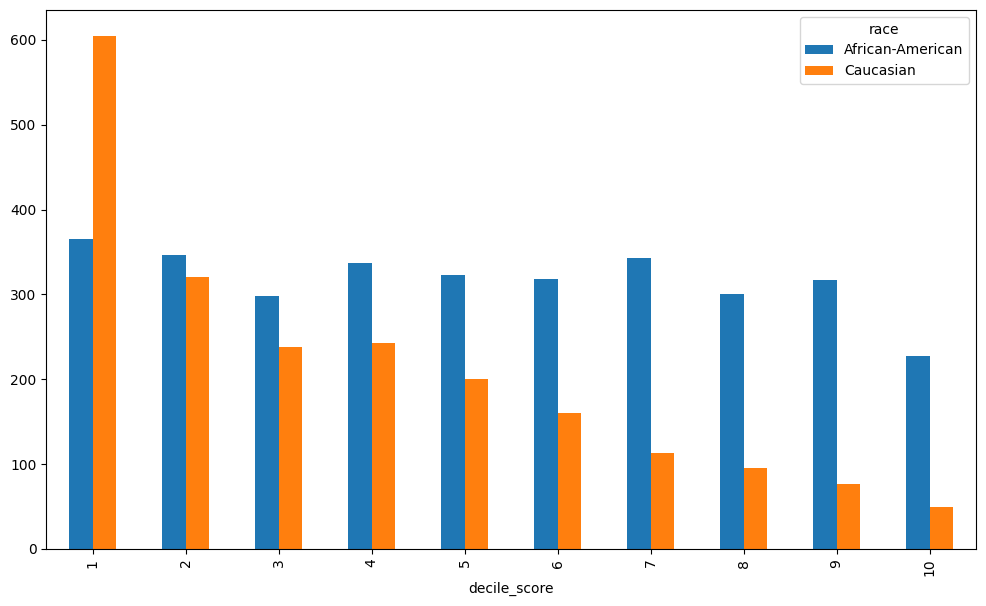
race_score_counts.T
| race | African-American | Caucasian |
|---|---|---|
| decile_score | ||
| 1 | 365 | 605 |
| 2 | 346 | 321 |
| 3 | 298 | 238 |
| 4 | 337 | 243 |
| 5 | 323 | 200 |
| 6 | 318 | 160 |
| 7 | 343 | 113 |
| 8 | 301 | 96 |
| 9 | 317 | 77 |
| 10 | 227 | 50 |
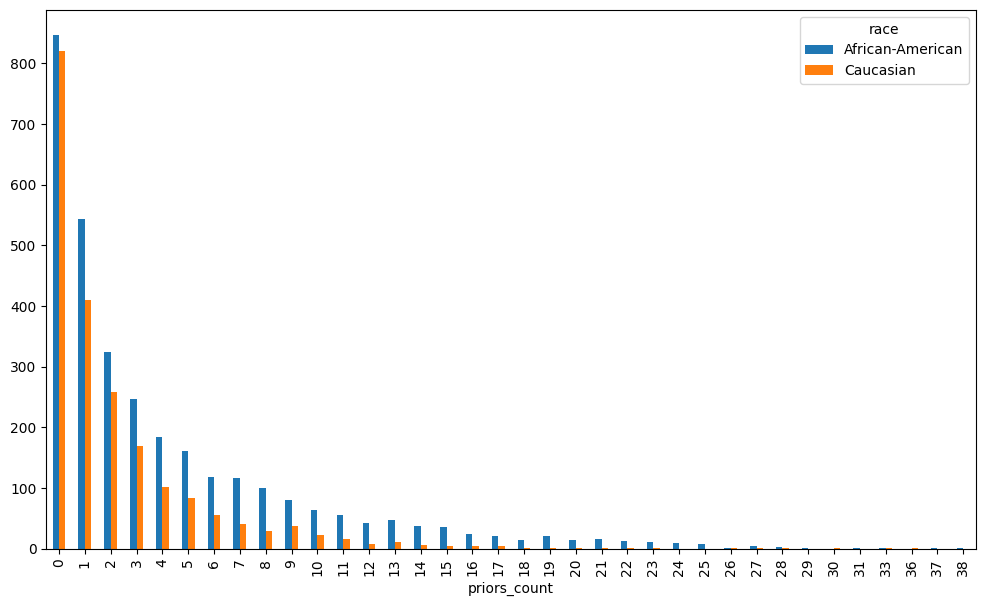
race_priors_counts = df.groupby('priors_count')['race'].value_counts().unstack()
race_priors_counts
| race | African-American | Caucasian |
|---|---|---|
| priors_count | ||
| 0 | 846.0 | 821.0 |
| 1 | 543.0 | 410.0 |
| 2 | 325.0 | 258.0 |
| 3 | 247.0 | 170.0 |
| 4 | 185.0 | 102.0 |
| 5 | 161.0 | 84.0 |
| 6 | 118.0 | 55.0 |
| 7 | 116.0 | 41.0 |
| 8 | 101.0 | 29.0 |
| 9 | 80.0 | 38.0 |
| 10 | 64.0 | 22.0 |
| 11 | 55.0 | 17.0 |
| 12 | 43.0 | 8.0 |
| 13 | 48.0 | 11.0 |
| 14 | 37.0 | 7.0 |
| 15 | 36.0 | 5.0 |
| 16 | 25.0 | 4.0 |
| 17 | 21.0 | 5.0 |
| 18 | 15.0 | 2.0 |
| 19 | 21.0 | 1.0 |
| 20 | 14.0 | 2.0 |
| 21 | 17.0 | 1.0 |
| 22 | 13.0 | 2.0 |
| 23 | 11.0 | 1.0 |
| 24 | 9.0 | NaN |
| 25 | 8.0 | NaN |
| 26 | 2.0 | 1.0 |
| 27 | 5.0 | 1.0 |
| 28 | 3.0 | 2.0 |
| 29 | 2.0 | NaN |
| 30 | NaN | 1.0 |
| 31 | 1.0 | NaN |
| 33 | 1.0 | 1.0 |
| 36 | NaN | 1.0 |
| 37 | 1.0 | NaN |
| 38 | 1.0 | NaN |
race_priors_counts.plot(kind= 'bar',figsize=(12,7))
<Axes: xlabel='priors_count'>
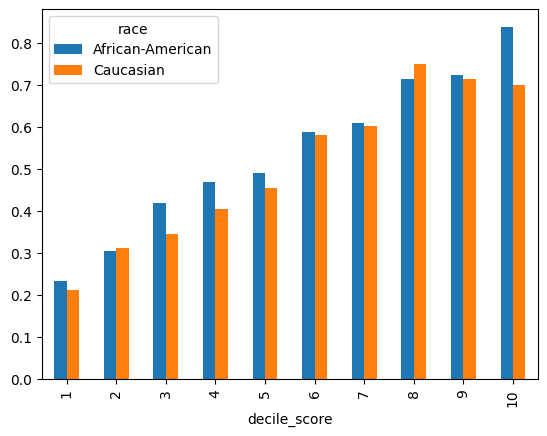
df.groupby(['race','decile_score'])['two_year_recid'].mean().unstack().T.plot(kind= 'bar')
#If I was compas, I would WANT basically the numbers to be flipped (higher not arrest, lower re-arrest)
<Axes: xlabel='decile_score'>
dfQ = pd.read_csv('https://raw.githubusercontent.com/ml4sts/outreach-compas/main/data/compas_cq.csv')
dfQ.head(1)
| id | age | c_charge_degree | race | age_cat | score_text | sex | priors_count | days_b_screening_arrest | decile_score | is_recid | two_year_recid | c_jail_in | c_jail_out | length_of_stay | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 34 | F | African-American | 25 to 45 | 0 | Male | 0 | -1.0 | 3 | 1 | 1 | 2013-01-26 03:45:27 | 2013-02-05 05:36:53 | <3months |
dfQ[['two_year_recid','score_text',]].corr()
| two_year_recid | score_text | |
|---|---|---|
| two_year_recid | 1.000000 | 0.314698 |
| score_text | 0.314698 | 1.000000 |
dfQ.groupby(['race','score_text'])[['two_year_recid']].mean()
| two_year_recid | ||
|---|---|---|
| race | score_text | |
| African-American | 0 | 0.351412 |
| 1 | 0.649535 | |
| Caucasian | 0 | 0.289979 |
| 1 | 0.594828 |
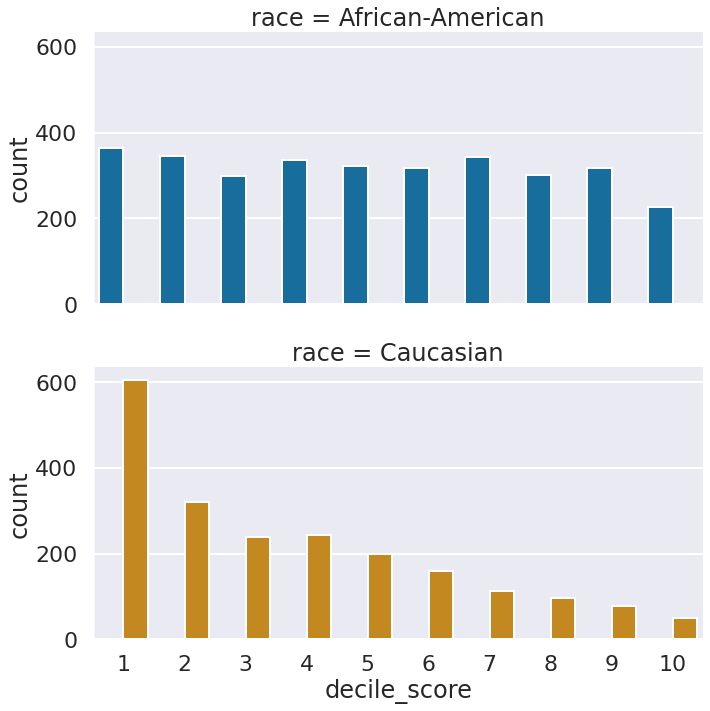
race_counts_df = df.groupby(['race','decile_score'])['two_year_recid'].count().reset_index().rename(
columns={'two_year_recid':'count'})
race_counts_df
| race | decile_score | count | |
|---|---|---|---|
| 0 | African-American | 1 | 365 |
| 1 | African-American | 2 | 346 |
| 2 | African-American | 3 | 298 |
| 3 | African-American | 4 | 337 |
| 4 | African-American | 5 | 323 |
| 5 | African-American | 6 | 318 |
| 6 | African-American | 7 | 343 |
| 7 | African-American | 8 | 301 |
| 8 | African-American | 9 | 317 |
| 9 | African-American | 10 | 227 |
| 10 | Caucasian | 1 | 605 |
| 11 | Caucasian | 2 | 321 |
| 12 | Caucasian | 3 | 238 |
| 13 | Caucasian | 4 | 243 |
| 14 | Caucasian | 5 | 200 |
| 15 | Caucasian | 6 | 160 |
| 16 | Caucasian | 7 | 113 |
| 17 | Caucasian | 8 | 96 |
| 18 | Caucasian | 9 | 77 |
| 19 | Caucasian | 10 | 50 |
sns.set_theme(context='poster', style='darkgrid', palette='colorblind', font='sans-serif', font_scale=1, color_codes=True, rc=None)
sns.catplot(data=None, *, x=None, y=None, hue='race', col=None, col_wrap=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, units=None, seed=None, order=None, hue_order=None, row_order=None, col_order=None, height=5, aspect=1, kind='strip', native_scale=False, formatter=None, orient=None, color=None, palette=None, hue_norm=None, legend='auto', legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, ci='deprecated', **kwargs)
Cell In[19], line 1
sns.catplot(data=None, *, x=None, y=None, hue='race', col=None, col_wrap=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, units=None, seed=None, order=None, hue_order=None, row_order=None, col_order=None, height=5, aspect=1, kind='strip', native_scale=False, formatter=None, orient=None, color=None, palette=None, hue_norm=None, legend='auto', legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, ci='deprecated', **kwargs)
^
SyntaxError: iterable argument unpacking follows keyword argument unpacking
race_counts_df.head()
| race | decile_score | count | |
|---|---|---|---|
| 0 | African-American | 1 | 365 |
| 1 | African-American | 2 | 346 |
| 2 | African-American | 3 | 298 |
| 3 | African-American | 4 | 337 |
| 4 | African-American | 5 | 323 |
sns.catplot(data= race_counts_df, x='decile_score',
y= 'count',
kind= 'bar',
row= 'race',
hue= 'race',
aspect= 2)
<seaborn.axisgrid.FacetGrid at 0x7fc4ae3354a8>
race_priors_counts.plot(kind= 'bar',figsize=(12,7))
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-3-7c7a5fac5bd5> in <module>
----> 1 race_priors_counts.plot(kind= 'bar',figsize=(12,7))
NameError: name 'race_priors_counts' is not defined